今日头条推荐系统:P1 概述
我们优化的目标是什么?用户满意度
我们正在寻找以下最佳 function 以最大化 用户满意度 。
用户满意度 = function(内容, 用户资料, 上下文)
- 内容:文章、视频、用户生成内容短视频、问答等的特征。
- 用户资料:兴趣、职业、年龄、性别和行为模式等。
- 上下文:在工作空间、通勤、旅行等情况下的移动用户。
如何评估满意度?
-
可测量的目标,例如:
- 点击率
- 会话持续时间
- 点赞
- 评论
- 转发
-
难以测量的目标:
- 广告和特殊类型内容(问答)的频率控制
- 低俗内容的频率控制
- 减少点击诱饵、低质量、恶心内容
- 强制/置顶/高度权重重要新闻
- 低权重来自低级账户的内容
如何优化这些目标?机器学习模型
找到上述最佳 function 是一个典型的监督机器学习问题。为了实施该系统,我们有以下算法:
- 协同过滤
- 逻辑回归
- 深度神经网络
- 因子分解机
- GBDT
一个世界级的推荐系统应该具备 灵活性,以进行 A/B 测试并结合上述多种算法。现在结合逻辑回归和深度神经网络变得流行。几年前,Facebook 使用了逻辑回归和 GBDT。
模型如何观察和测量现实?特征工程
-
内容特征与用户兴趣之间的相关性。 显式相关性包括关键词、类别、来源、类型。隐式相关性可以从 FM 等模型的用户向量或项目向量中提取。
-
环境特征,如地理位置、时间。 可以用作偏见或在其基础上建立相关性。
-
热门趋势。 有全球热门趋势、类别热门趋势、主题热门趋势和关键词热门趋势。热门趋势在我们对用户信息较少时非常有助于解决冷启动问题。
-
协同特征,帮助避免推荐内容越来越集中。 协同过滤不是单独分析每个用户的历史,而是根据用户的点击、兴趣、主题、关键词或隐式向量找到用户的相似性。通过找到相似用户,可以扩展推荐内容的多样性。
实时大规模训练
- 用户喜欢看到根据我们从他们的行为中跟踪到的内容实时更新的新闻源。
- 使用 Apache Storm 实时训练数据(点击、展示、收藏、分享)。
- 收集数据到达阈值后更新推荐模型
- 在高性能计算集群中存储模型参数,如数十亿的原始特征和数十亿的向量特征。
它们的实现步骤如下:
- 在线服务实时记录特征。
- 将数据写入 Kafka
- 从 Kafka 向 Storm 导入数据
- 填充完整的用户资料并准备样本
- 根据最新样本更新模型参数
- 在线建模获得新知识
如何进一步减少延迟?召回策略
考虑到所有内容的超大规模,无法用模型预测所有事情。因此,我们需要召回策略来关注数据的代表性子集。性能在这里至关重要,超时时间为 50 毫秒。
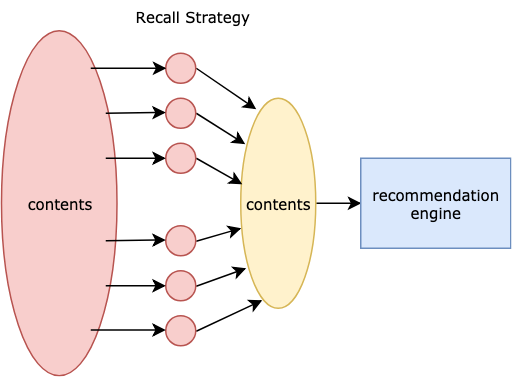
在所有召回策略中,我们采用 InvertedIndex<Key, List<Article>> 。
Key 可以是主题、实体、来源等。
| 兴趣标签 | 相关性 | 文档列表 |
|---|---|---|
| 电子商务 | 0.3 | … |
| 娱乐 | 0.2 | … |
| 历史 | 0.2 | … |
| 军事 | 0.1 | … |
数据依赖
- 特征依赖于用户端和内容端的标签。
- 召回策略依赖于用户端和内容端的标签。
- 用户标签的内容分析和数据挖掘是推荐系统的基石。
什么是内容分析?
内容分析 = 从原始文章和用户行为中推导中间数据。
以文章为例。为了建模用户兴趣,我们需要对内容和文章进行标记。为了将用户与“互联网”标签的兴趣关联起来,我们需要知道用户是否阅读了带有“互联网”标签的文章。
我们为什么要分析这些原始数据?
我们这样做的原因是 …
- 标记用户(用户资料)
- 标记喜欢带有“互联网”标签的文章的用户。标记喜欢带有“小米”标签的文章的用户。
- 通过标签向用户推荐内容
- 向带有“小米”标签的用户推送“小米”内容。向带有“Dota”标签的用户推送“Dota”内容。
- 按主题准备内容
- 将“德甲”文章放入“德甲主题”。将“饮食”文章放入“饮食主题”。
案例研究:一篇文章的分析结果
这是“文章特征”页面的示例。文章特征包括分类、关键词、主题、实体。
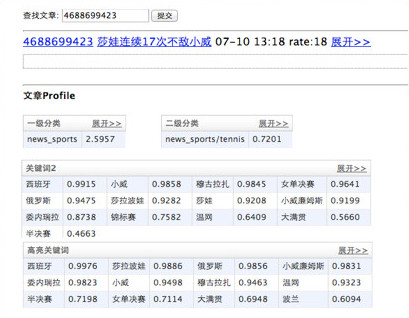
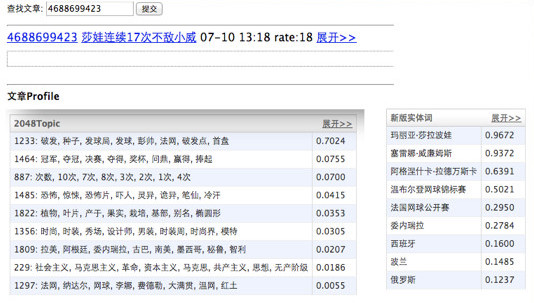
文章特征是什么?
-
语义标签:人类预定义这些标签并赋予明确的含义。
-
隐式语义,包括主题和关键词。主题特征描述了单词的统计信息。某些规则生成关键词。
-
相似性。重复推荐曾是我们客户反馈中最严重的问题。
-
时间和地点。
-
质量。滥用、色情、广告或“心灵鸡汤”?
文章特征的重要性
- 推荐系统并非完全无法在没有文章特征的情况下工作。亚马逊、沃尔玛、Netflix 可以通过协同过滤进行推荐。
- 然而,在新闻产品中,用户消费的是同一天的内容。没有文章特征的引导是困难的。协同过滤无法帮助引导。
- 文章特征的粒度越细,启动的能力越强。
更多关于语义标签
我们将语义标签的特征分为三个层次:
- 分类:用于用户资料、过滤主题内容、推荐召回、推荐特征
- 概念:用于过滤主题内容、搜索标签、推荐召回(喜欢)
- 实体:用于过滤主题内容、搜索标签、推荐召回(喜欢)
为什么要分为不同层次?我们这样做是为了能够以不同的粒度捕捉文章。
- 分类:覆盖全面,准确性低。
- 概念:覆盖中等,准确性中等。
- 实体:覆盖低,准确性高。它仅覆盖每个领域的热门人物、组织、产品。
分类和概念共享相同的技术基础设施。
我们为什么需要语义标签?
- 隐式语义
- 一直运作良好。
- 成本远低于语义标签。
- 但是,主题和兴趣需要一个明确的标记系统。
- 语义标签还评估了公司在 NPL 技术方面的能力。
文档分类�
分类层次结构
- 根
- 科学、体育、金融、娱乐
- 足球、网球、乒乓球、田径、游泳
- 国际、国内
- A 队、B 队
分类器:
- SVM
- SVM + CNN
- SVM + CNN + RNN
计算相关性
- 对文章进行词汇分析
- 过滤关键词
- 消歧义
- 计算相关性