Designing typeahead search or autocomplete
· 2 min read
Requirements
- realtime / low-latency typeahead and autocomplete service for social networks, like Linkedin or Facebook
- search social profiles with prefixes
- newly added account appear instantly in the scope of the search
- not for “query autocomplete” (like the Google search-box dropdown), but for displaying actual search results, including
- generic typeahead: network-agnostic results from a global ranking scheme like popularity.
- network typeahead: results from user’s 1st and 2nd-degree network connections, and People You May Know scores.
Architecture
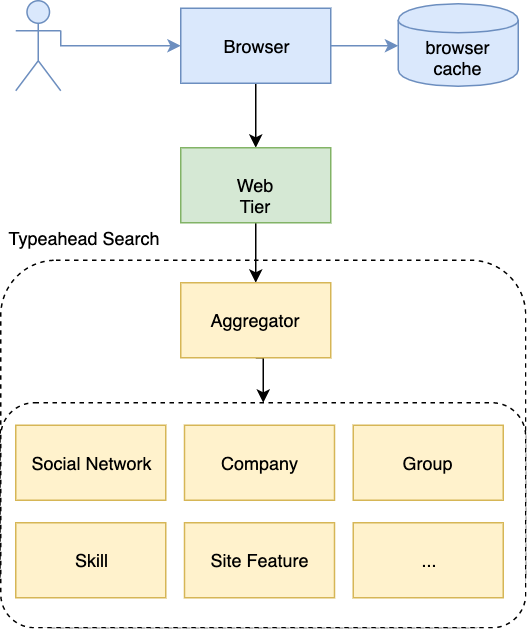
Multi-layer architecture
- browser cache
- web tier
- result aggregator
- various typeahead backend
Result Aggregator
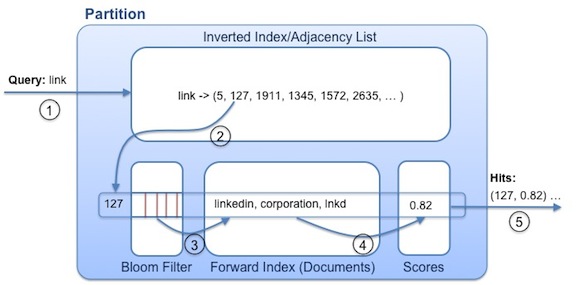
The abstraction of this problem is to find documents by prefixes and terms in a very large number of elements. The solution leverages these four major data structures:
InvertedIndex<prefixes or terms, documents>: given any prefix, find all the document ids that contain the prefix.for each document, prepare a BloomFilter<prefixes or terms>: with user typing more, we can quickly filter out documents that do not contain the latest prefixes or terms, by check with their bloom filters.ForwardIndex<documents, prefixes or terms>: previous bloom filter may return false positives, and now we query the actual documents to reject them.scorer(document):relevance: Each partition return all of its true hits and scores. And then we aggregate and rank.
Performance
- generic typeahead: latency < = 1 ms within a cluster
- network typeahead (very-large dataset over 1st and 2nd degree network): latency < = 15 ms
- aggregator: latency < = 25 ms